DynamoDB key concepts
In this post, we’ll be diving into the key concepts of DynamoDB. So, let’s get started!
1. Key-Value Database
Let’s say that you want to store information about a list of customers, including their name, email, and phone.
In a key-value database, each customer would be stored as a separated item, with a unique key that identifies that customer. For example:
Key: Customer1
Value:
{
"name":"Ahmad Mayahi",
"email":"ahmad@mayahi.net",
"phone":"0123456789"
}
With this key-value model, you can quickly retrieve all the information related to a particular customer by using the key.
But what is the difference between key-value and RDBMS (such as MySQL)?
The main difference between a key-value database and a key-column database (such as MySQL) lies in their data modeling and querying capabilities.
A key-value database uses a simple key-value pair to represent and organize the data.
In our example, all the customer’s data is stored as a single value and the value is associated with a unique identifier called a key.
While the value is technically a single entity, it can contain a variety of attributes representing the associated data. In our examples, I used JSON format to represent these attributes.
Sounds confusing?
No problem, let me clarify it in other words.
When storing customer data in DynamoDB, you’re actually sending a set of attributes that represent the customer’s data (name, email, phone, etc…), similar to MySQL’s fields.
Just imagine that the customer’s data is in JSON format.
While DynamoDB does store all these attributes as a single entity (under the hood), you won’t notice this because you can still view and interact with the attributes individually.
However, you cannot perform queries on attributes other than the primary key unless you create a secondary-index that includes the phone attribute.
I will explain the
primary-keyandsecondary-indexeslater in this post.
If we want to represent a key-value pair in RDBMS then all we need to do is to create a table consisting of two fields, key and value as follows:
CREATE TABLE customers (
`key` VARCHAR NOT NULL UNIQUE,
`value` TEXT NOT NULL,
PRIMARY KEY (`key`)
);
Inserting a new customer:
INSERT INTO customers SET id = 'User#123', value = '{"name":"Ahmad Mayahi","email":"ahmad@mayahi.net","phone":"0123456789"}';
How about key-column?
With key-column databases (such as MySQL), data is stored in separated columns, allowing us to perform flexible queries on individual fields.
This is in contrast to key-value databases, where queries are typically restricted to the primary-key.
For example, in MySQL, we can easily query on the phone field as follows:
SELECT * FROM customers WHERE phone = '9999';
Whereas in DynamoDB, we can only query on the primary key:
$dynamodb = new Aws\DynamoDb\DynamoDbClient([
'region' => 'eu-central-1',
'version' => 'latest'
]);
// Execute the query
$result = $dynamodb->query([
'TableName' => 'customers',
'KeyConditionExpression' => 'id = :id',
'ExpressionAttributeValues' => [
':id' => ['S' => '123']
]
]);
2. Schemaless
Unlike traditional relational databases such as MySQL, which requires you to define the schema upfront and strictly enforce it, DynamoDB allows you to add or modify data without a predefined schema.
However, it is important to note that having a schema in your application layer is still necessary to ensure that the data being stored is structured and consistent. So the schema can be enforced through code and data validation checks at the application level rather than relying on the database to enforce it.
For example, in Laravel applications, the $fillable property can be used to specify the attributes (fields) of a model. Any attributes outside of the defined ones will be declined.
3. Table, Items, Attributes and Item Collection
DynamoDB, stores data in tables, just like any RDBMS. However, as mentioned earlier, the key difference is that DynamoDB does not enforce a strict schema on the table.
-
Item: Refers to a single data record within a table, much like a row in a MySQL table. -
Attribute: Represents a single piece of data within an item, similar to fields in MySQL.
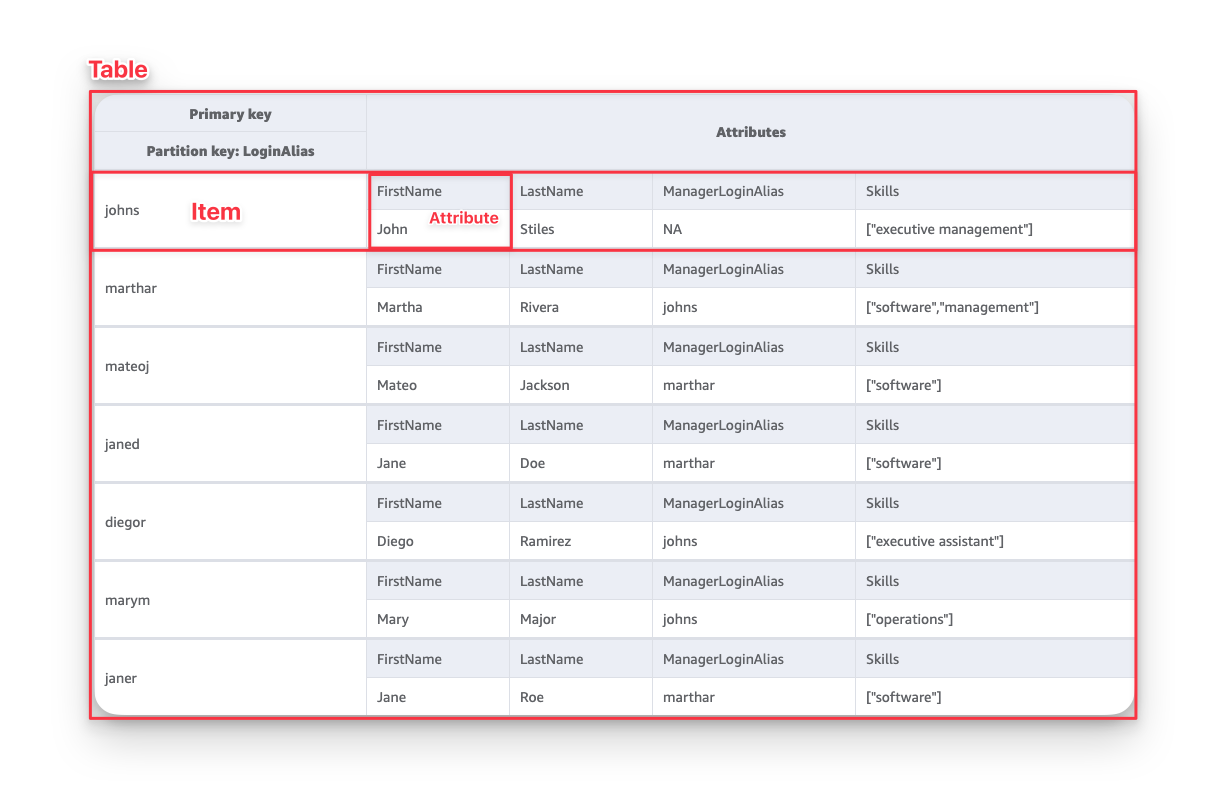
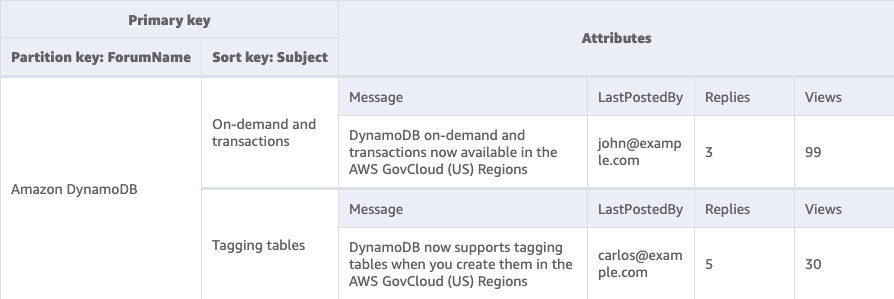
The item collection is a group of items that share the same partition key - I will discuss partition keys later - .
For example, here I have two items that share the same partition key Amazon DynamoDB:
4. Primary-key
The primary key is a unique identifier for each item in a table.
In contrast to MySQL, DynamoDB does not have an AUTO_INCREMENT option available. This means that every time you create a new item, you must manually specify the ID.
If you’re using MySQL, you can query on all the fields, for example you can write something like this:
SELECT * FROM customers WHERE phone = '0123456789';
However, querying on attributes other than the primary key is not possible in DynamoDB.
Let me explain this.
As I mentioned earlier, the value associated with a key is a single entity that contains all the attributes of that item, whereas in MySQL, fields are saved individually in a row of a table.
But what if I want to query by the phone number? How would I do that?
In order to do that, you must create what so-called a secondary-index for that particular attribute.
But before I delve into that, let’s talk about the partition-key and sort-key in DynamoDB.
5. Partitions
In DynamoDB, the primary key consist of two attributes:
- Partition key (mandatory)
- Sort key (optional)
When you make a write request to DynamoDB, the database system takes the item you want to store and stores it into the appropriate partition based on the partition key.
But what is the partition?
According to the DynamoDB documentation, the partition refers to a portion of storage dedicated to a table, which is supported by solid-state drives (SSDs) and automatically replicated across several Availability Zones in a given AWS Region.
For example, if you have a table that is 10 GB in size and you wish to query data for a specific partition key, such as User#123, DynamoDB can locate the partition containing the data for that key, even though the data is dispersed across multiple SSD drives / servers. DynamoDB can identify which server contains the storage for the User#123 partition key by just looking at the primary-key.
Under the hood, DynamoDB uses a hash function to determine the partition where the item should be stored based on the value of the partition key attribute.
6. Sort-key
The sort-key (also known as “range key”) is specifically used to sort items with the same partition, and allows you to perform range queries, which retrieve items based on a range of partition key values and/or a range of sort key values.
Suppose you have a table called “orders” and you need to retrieve the orders placed between 01 Jan 2023 and 01 Jan 2024. This can be accomplished by following the steps below:
$result = $dynamodb->query([
'TableName' => 'orders',
'KeyConditionExpression' => 'customer_id = :customerId AND order_date BETWEEN :startDate AND :endDate',
'ExpressionAttributeValues' => [
':customerId' => ['S' => '12345'],
':startDate' => ['S' => '2023-01-01'],
':endDate' => ['S' => '2024-01-01']
]
]);
7. Secondary Indexes
To be able to query a specific attribute on a table, you have to create a secondary index.
This type of index allows us for querying the table using attributes other than the primary key.
For instance, if we want to find customers by their phone number, we can create a secondary index that uses the phone attribute as a primary key.
I know, secondary indexes can be confusing, however, in the upcoming posts, I will cover everything you need to know about them. Just remember, a secondary index is required if you want to query a field other than the primary key.